智能应用成本优化最佳实践
当前基于大语言模型构建的智能应用一但对外服务,都会面临成本的压力,该成本的主要部分可能是调用LLM产生的费用问题。 一般企业采购LLM的服务会有两种,一种是直接购买MAAS服务,按照token计费,一种是购买GPU算力进行开源模型托管
购买MAAS服务的优化方案
对于MAAS服务的成本优化,核心在如何利用好Multi-LLM,我们知道不同模型的调用费用是有差异的,比如GPT4的调用单价要远高于其他的基础模型。而在我们的复合型智能应用中,往往有多个场景需要用到基础模型的能力,并且对模型性能的要求并不相同,因此这里存在成本优化的空间,即对高性能要求的场景使用高级的模型,低性能的场景使用低性能的模型,从而更加合理优化模型调用的成本。AgentCraft目前虽然无法智能化的识别并路由到不同的模型服务,这也跟您自身的业务场景相关,但已经可以统一不同的基础模型的调用,通过基础模型部署和LLM代理配置可以无缝的在智能体中切换基础模型,比如单纯的文本提取或者内容转化类的场景,你可以使用开源的零一,LLama2等模型,而对于复杂推理的智能助手应用你可以采用qwen-plus或者gpt4 下面附上一些平台免费领取token的介绍,可以拿到价值大约300-400RMB的 token调用
阿里云灵积平台
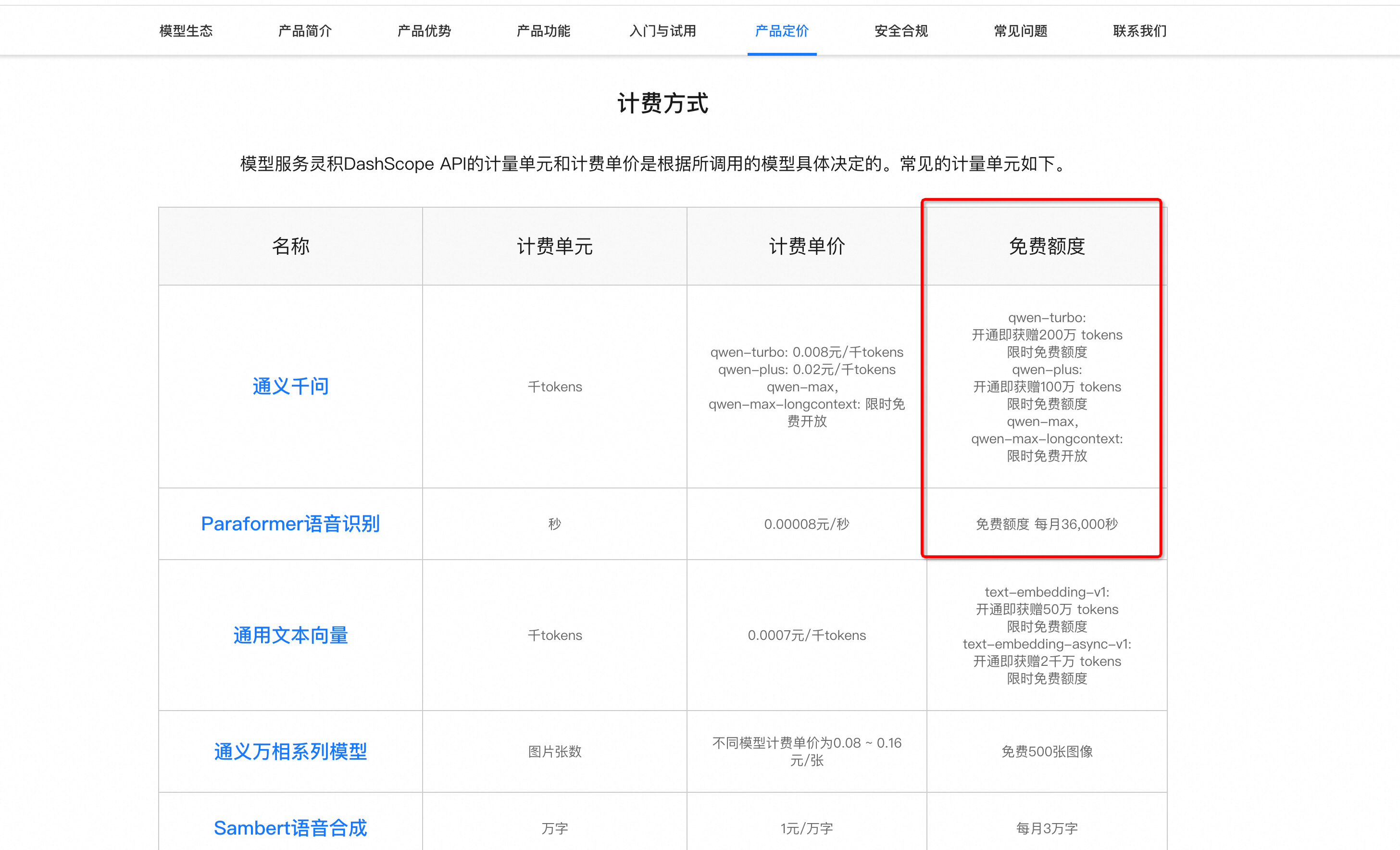
可以获取价值36RMB的免费token
-
登录灵积控制台,获取apiKey
-
AgentCraft创建对应的服务
智普AI 开放平台
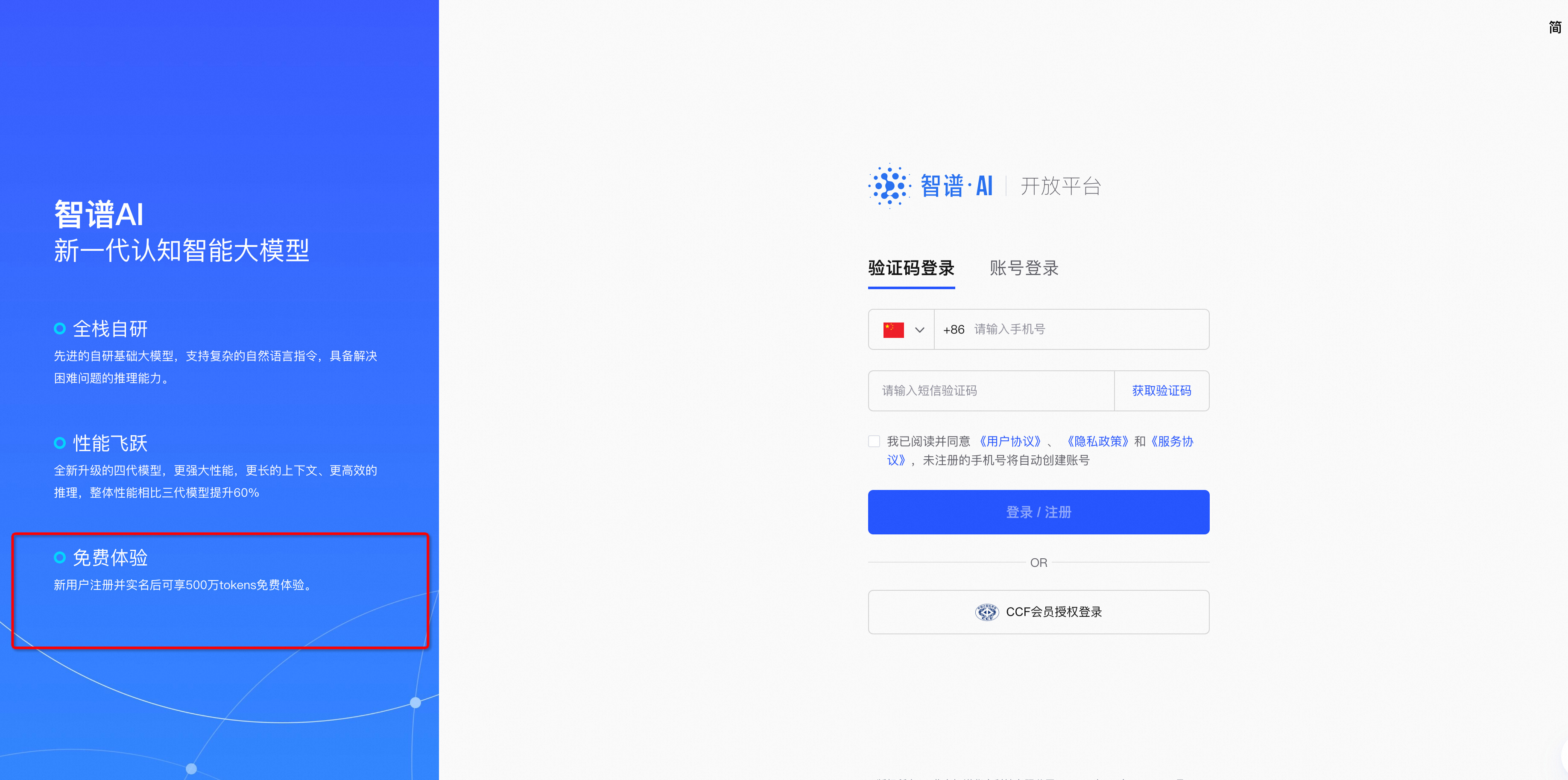
可以获取500W免费token,价值25-500RMB

TogetherAI
可以获取价值 175RMB的免费额度(25$)
-
访问TogetherAI查看
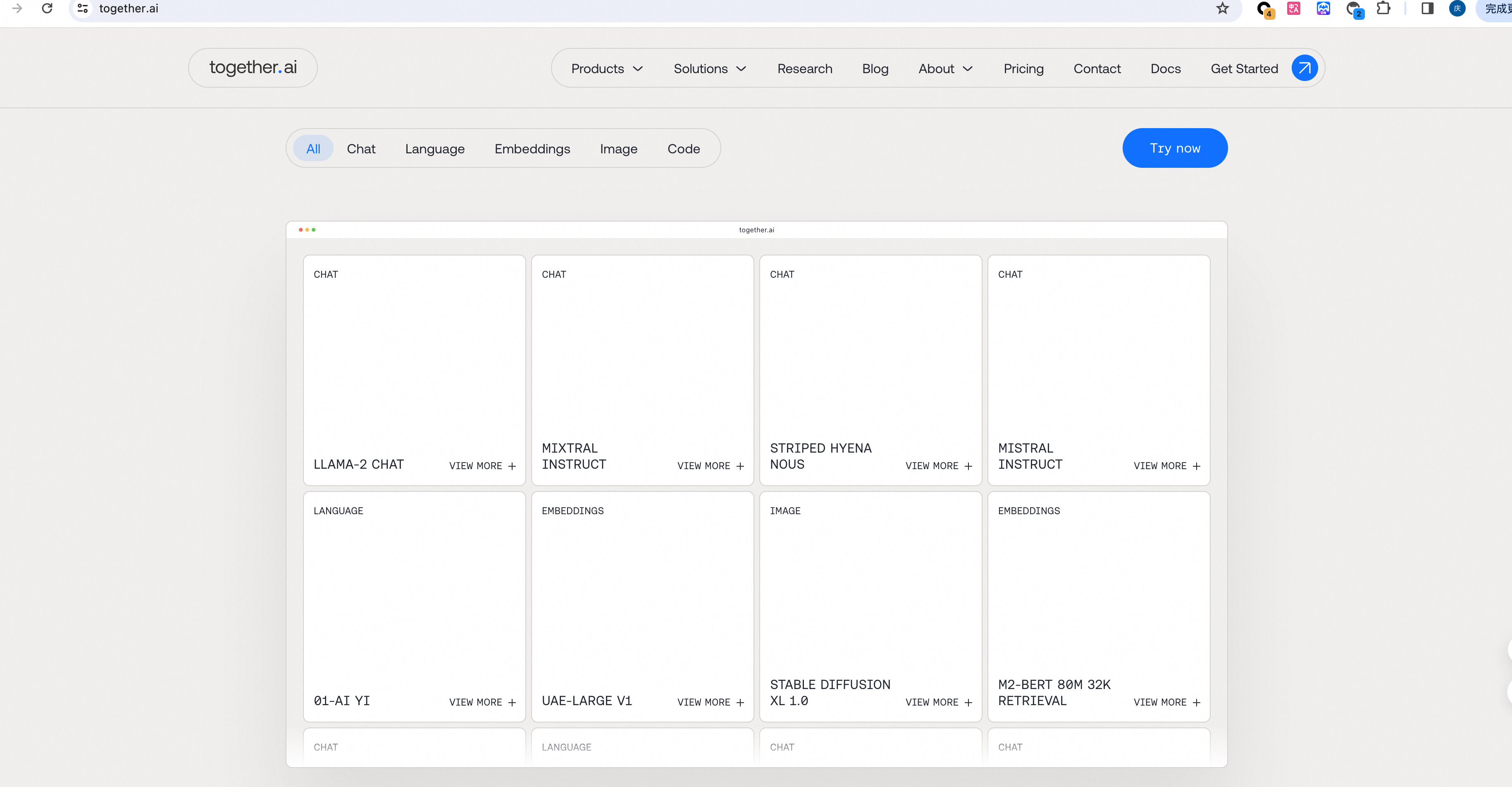
-
登录TogetherAI,获取apiKey
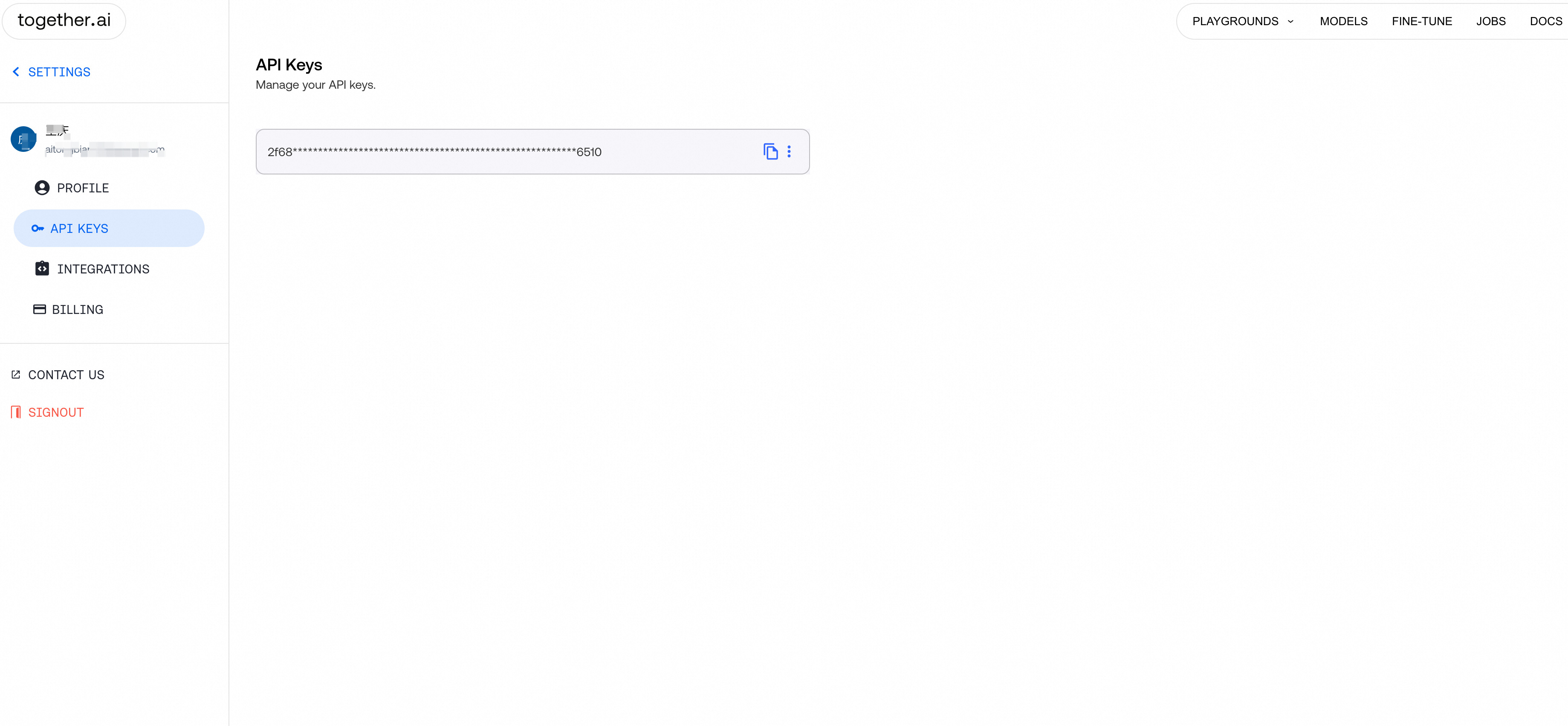
-
AgentCraft创建对应的服务
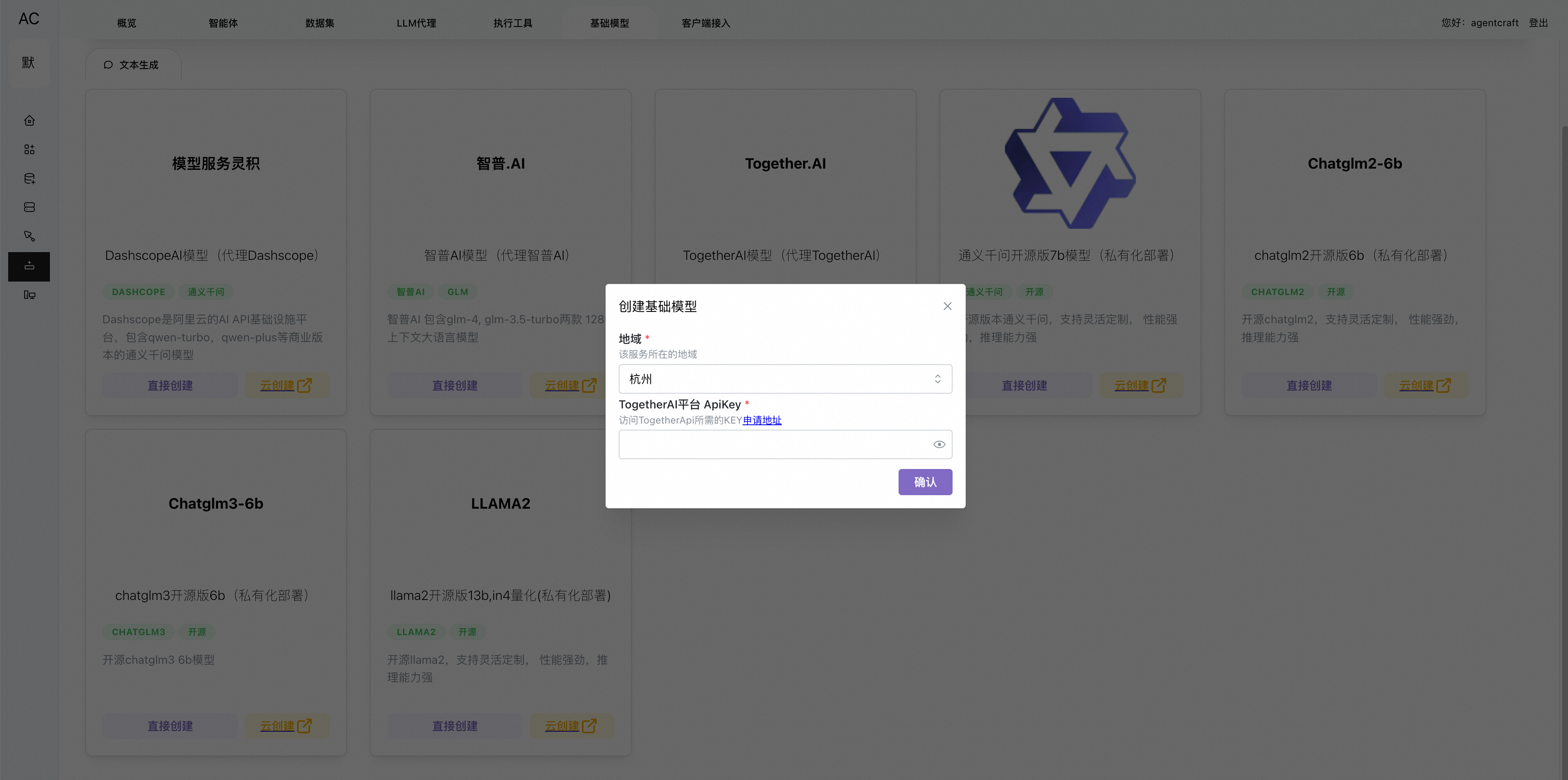
更多TODO
- lepton
- 月之暗面
购买算力进行开源模型托管的优化方案
基础算力的成本优化核心有几点
- 1.购买的算力足够便宜,这个跟采购供应商相关,他们提供的基础费用及折扣率决定该成本
- 2.优化推理,将每秒输出的token数量大幅增加
- 3.客户层面按量计费,当用户的应用无请求应当少计费甚至不计费来节省资源成本 当然要实现2,3方案需要相当的技术投入,还得做好效果的平衡,下面方案是以第三点为切入,阿里云函数计算推出了显示计费的模式,可以在保障性能的前提下,帮助您大幅降低GPU的成本开销。
详细请参考文章《基于函数计算快速搭建低成本LLM应用》